








































































Webinar Recap: How to Tame the Chaos of Enterprise Vulnerability Management
This is a recap and transcription of our webinar presentation “How to Tame the Chaos of Enterprise Vulnerability Management,” originally recorded live on December 7th, 2022. To watch the original recording, check out the video below.
In this webinar, we’re going to be focused on talking about how to tame the chaos of enterprise vulnerability management. One thing I do want to highlight as we hop in is a significant amount of this is very educational in talking about how to approach vulnerability management and some of the considerations now in market shift. So, I just want to highlight the importance of that educational factor during this webinar. We have two special guests, two of the co-founders at Nucleus Security and practitioners in vulnerability management for a long time working with federal government, large enterprises, and the likes, understanding that there is a real challenge of vulnerability management at scale. So with us, we have Steve Carter, CEO of Nucleus, and Scott Kuffer, COO and co-founder, joining as well.
Before we hop in, let’s give a quick overview and understanding of Nucleus for people before we hop into the educational portion of the section on taming the chaos of enterprise vulnerability management.
Nucleus and the Chaos Vulnerability Management
Steve: If you’re not familiar with Nucleus Security, we’re really a company that’s on a mission to prevent breaches and reduce risk through the automation of risk-based vulnerability management. That’s the best way I would sum up what we do. And really what inspired us to talk about this topic today is that we hear this word chaos a lot from our customers, from our prospects when they describe the state of their vulnerability management programs, which is often in the state of disorder, state of unpredictability, and generally these newer customers that haven’t fully implemented Nucleus yet, but we’ve noticed that perceived this chaos, it usually stems from a few different issues.
So, the idea to today is really just to share some of our thoughts and ideas on how to address some of these issues and pain points that we hear so commonly and some of these reasons why vulnerability management can just really be such a challenge in large enterprises. Really everything we’re going to talk about today can be done with or without Nucleus. We’re not here to sell the product to you, but at the end we will be giving a quick tour of Nucleus specifically to show you how some of the things that we talk about can be implemented and done in practice and what good looks like, quite frankly. So be sure to hang around for that.
The Current State of Vulnerability Management
Steve: I want to take just a minute to talk about what’s changed, because the vulnerability management space has been around for a long time – over 25 years. Going back to the late nineties, really it was really all about vulnerability scanning and patching. So you had generally a guy or a gal from IT who knew something about security. They would operate a scanning tool and they would work with the rest of the IT team to get patches deployed based on what those tools told them to do. And a whole lot has changed in that time, and we’ve added a ton of scope and complexity to this domain of vulnerability management.
So for starters, we had the emergence of the cloud. 10-15 years ago, we had DevOps come along and we had the shift left movement and a lot of other advances in technology, some of which I list out here on the left hand of the slide. And in response to that, thankfully we had a lot of advances in vulnerability scanning technology, and pretty quickly went from a world where an organization, a large organization could get by with some patch management tools and a handful of scanners maybe to a world where you need 10 to 20 different tools sometimes to continuously scan and detect vulnerabilities and all the different layers and components. And what’s become a very complex technology stack for a lot of organizations.
So you still have your traditional scanners, your Tenables and Rapid7s and whatnot, but you also have application scanning tools and cloud security posture management tools and open source library tools and much, much more. All these things kind of list out here in the center. But monthly scanning or even quarterly scanning, what used to get the job done just doesn’t get the job done any longer because attackers are exploiting new vulnerabilities faster than they ever have before. Now, on average, within 15 days of being publicly announced, the vulnerability is going to be exploited if it’s going to be exploited at all. And so we’ve seen in the last couple of years record numbers of zero day vulnerabilities. And in a lot of those cases, exploitation was happening days or sometimes weeks before the patch was even available.
So bottom line is speed is more important now, speed to triage, to remediate, it’s more important now than it’s ever been. And then finally, of course, with all this continuous scanning, with all these tools, you generate a massive amount of vulnerability information and data that you have to do something with, you have to make it actionable, you have to analyze it, you have to triage it, all this data comes in different formats, in different shapes and sizes, and it can be a massive engineering undertaking just to make it actionable, just to make sense of it all. So that’s really what’s changed.
The Pain Points of Vulnerability Management

Steve: At Nucleus, we work a lot with vulnerability management practitioners, really in a wide range of roles. Everything from IT security folks to security architects and engineers, all the way to product security teams and developers. And when we ask them, and we ask them all the time, what are the biggest challenges and pain points relating to VM that they have? They generally mention one or sometimes multiple of the things in this list. Really in no particular order, this isn’t a prioritized list, but vulnerability prioritization issues really are extremely common, especially in large enterprises. And one of the big reasons why I think is that the people performing analysis of vulnerability scans, they’re taking the vulnerability severities that the tools give them and the data that’s given to them at face value.
And this is problematic for a lot of reasons. Most vulnerability scan tools today are still based on CVSS scores, which are severity and impact is what they measure, they’re not really indicative of risk. And that’s a big problem in and of itself. But even beyond that, one tool might have three levels of severities: a high, moderate, low. Another might have five levels. So without any kind of normalization across your tooling, you kind of hit a brick wall pretty quickly when it comes to vulnerability prioritization.
Slow remediation timelines, I think the average mean meantime to remediate high risk vulnerabilities today is between 60, 90 days depending on what sector you’re in. And I’m sure probably everyone on this call has seen really firsthand how long it can take to mitigate vulnerabilities like Log4J. Log4J’s been out for right at a year now and I bet a lot of people on this call still probably have it lingering around their network. I hope you don’t, but nothing to be really ashamed of. In fact, I empathize with that a lot because I’ve been there and the struggle’s real. But there are a lot of reasons for this that we could go into.
I can tell you in most cases when we start digging deeper here, we still see a lot of organizations, even mid and large size organizations that still live in what we call spreadsheet hell, where they’re mostly doing manual processes, they’re mostly passing around trackers and spreadsheets, they’ve got these processes that worked when the organization was smaller, but they become bigger, their tech stacks become more complex, and now it’s become a bottleneck more and more over time. And so this inability to remediate quickly has just snowballed, become a larger and larger problem, especially when we’re seeing mass exploitation of newly discovered vulnerabilities, sometimes within minutes or hours of them being publicly disclosed. So, this is a really big and common problem here.
Really quick, let’s talk about reporting. We hear every day from companies that don’t have the ability to report and measure progress of their VM operation in a meaningful way. And you might have some scanning tools or detection tools that report on some information, but it’s fractured and there are gaps there. And what they really want is the ability to measure and report across all of their sources of vulnerability information, all of their scanning tools, all 10, 15, 20, sometimes in bigger organizations. But today, a lot of those organizations just can’t tell you what their mean time to remediate is across the organization, their MTTR, they can’t tell you even what their velocity is in terms of their ability to remediate vulnerabilities.
How many can they remediate in a month, in quarter? They don’t know. They’re unable to really measure that or report on that. And this is a tricky one because it can be a catch-22 in the sense that it’s hard to get corporate buy-in for a project to really modernize your vulnerability management program to get that corporate investment without the metrics to back it up. And unfortunately, what we see is sometimes it takes companies being breached due to a vulnerability exploit to really make that decision to improve their program. So increasing spend, I can’t tell you how often we hear from folks that are frustrated. They poured a lot of money, invested in a lot of money into the program, not a lot of evidence that the program’s performing any better. This could be related to the previous bullet point, their inability to measure, but in many cases they’re making investments and they’re not measurably really getting any better.
And those investments, they could be increasing headcount, they could be adding new scanning tools, building custom software sometimes to try to automate things. But if you don’t really have a sound framework, a sound policy around your vulnerability management program, it can just be really hard to see the ROI, especially when your enterprise is growing and growing and just maintaining performance takes an investment.
And then the last one here, vulnerability debt is increasing, meaning really that new vulnerabilities are surfacing in the organization faster than vulnerabilities can be remediated. So you’re accumulating this debt, and this is, I guess it’s kind of related to the second bullet point here about remediation timelines being slow. But what’s making the problem even worse is that each year around 25% more new vulnerabilities are discovered than the previous year. So this year I think we’re going to hit around 25,000 vulnerabilities, new vulnerabilities added to NVD. Last year I think it was around 18,000, 19,000, something like that. The point is that your vulnerability management program essentially needs to be about 25% better each year performance wise just to keep up and maintain status quo. So your investments might be working, but they still might not be enough to show a net increase in the performance of your program, if that makes sense.
Leveling Up Your Vuln Management
Steve: So, I want to shift gears for just a few moments here and talk about some of the most impactful things that you can do and in some cases stop doing to really level up your vulnerability management program. And I’ll assume that just about everyone on this call is intimately familiar with CVSS, which stands for the Common Vulnerability Scoring System. In my opinion, the worst thing about CVSS is that most people equate CVSS scores with risk scores. Still even today, even though the CVSS users guide states CVSS measures severity, not risk, no one reads the guide, that doesn’t really matter. But we’ve really been just trained by vendors and by vulnerability scanning and detection vendors, by the industry as a whole to think of CVSS in this way for the last 10, 15 years. And in most cases, it’s still the primary approach that vulnerability scanning vendors are using to prioritize.
There are definitely some exceptions to that. They’re getting better, but it’s still very pervasive. And so it might sound kind of crazy, but it can be a big undertaking in a lot of organizations just to change, just to educate folks and really change people’s understanding of a simple concept like CVSS and what it means. But that’s really key to getting change in the program. Aside from CVSS not measuring risk, there are other reasons why you don’t really want to rely on it for prioritization. The majority of vulnerabilities that get scored with CVSS scores come out as either high or critical severity. So I think for this year alone, the average for 2022 is around the score of 7.2 for all new vulnerabilities, which that’s categorized as a high severity. So with 60 to 70 new vulnerabilities coming out each day and being added to NVD each day, that’s 30 to 35 that are going to be critical or high severity. And that’s a big number when it comes to just thinking about the level of effort involved in processing all that information, doing the analysis, doing the triage.
The real kicker here though is that over 95% of those vulnerabilities will never be exploited. So think of all the time that’s that’s really being wasted, patching things that will never be exploited, that pose no risks, and more importantly, think of how much faster that we could remediate the 5% that will be exploited if we didn’t have to worry about the other 95%. And now I think everyone would probably agree that if we knew exactly which 5% we’re going to be exploited, we could only patch those and move on with our lives. Of course, we don’t have a crystal ball to tell us exactly with certainty what those 5% are that will be exploited in the future, but we do know today which vulnerabilities are being exploited or actively being exploited in the wild. And we have some great tools and great information to help us predict with a really high degree of certainty which vulnerabilities will be exploited in the future. So I think that’s probably a really good segue to my next slide where I want to talk about operationalizing vulnerability intelligence.
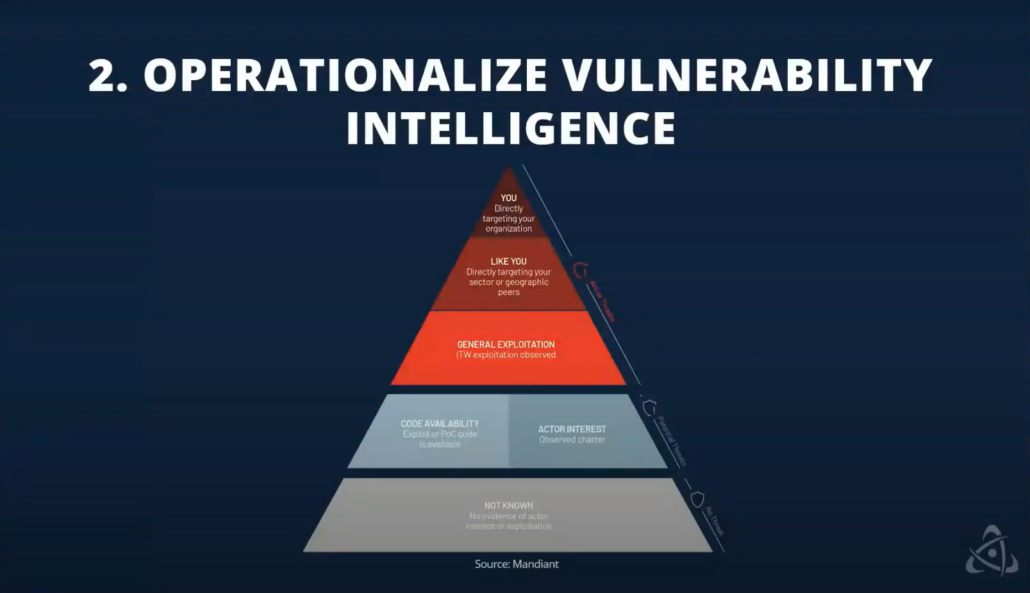
All right, so this is one of my favorite diagrams because it does such a good job of really illustrating which vulnerabilities out of those 5% that I mentioned that either are or will be exploited, which of those present the most risk to the organization? The problem with this diagram is that it can be somewhat misleading for an organization that’s really just starting to operationalize vulnerability intelligence because, in that case, the best place to start and the best place to focus isn’t really obvious because it’s in the middle, it’s really right in the center. And the objective here is to identify and mitigate vulnerabilities that are confirmed to be exploited in the wild. And keep in mind, this is a small subset of all vulnerabilities between three and 5%. And for a long time there really wasn’t a way to know which vulnerabilities have been or are being exploited in the wild.
That’s changed in the last, I don’t know, five years or so. There are now a lot of great sources out there, both free and paid for and commercial. If you’re just getting started, one of the ones we recommend that you look at is the system known exploited vulnerabilities list or the KEV. If you follow us on social or have heard us speak, we’ve been talking about that a lot lately. But it’s a very simple concept that they’ve implemented. It’s basically the KEV is a curated list of about 900 or so vulnerabilities. And in CISA’s words, it is the authoritative source of vulnerabilities that have been exploited in the wild. It’s not a perfect list and I could probably talk all day about ways it could be improved, but I still recommend that organizations start here for a few reasons.
One, I like the price, it’s free. Two, CISA, they’ve got great visibility into what’s happening in the wild, maybe better than any other organization in the world. And the information that they’re giving you in terms of this list of CVEs is just, it’s immediately actionable. It’s very high signal. It’s a single data point really. So there’s no ambiguity there. You can take that and do something with it today.
Moving down the list here, there are other sources of free information that are really good. You’ve got exploit sites and databases. Everyone’s heard of exploit DB, got dark web marketplaces where exploits are being sold, where you can see vulnerability exploits for sale, and obviously that means they’re, they’re exploitable. You’ve got tools like GreyNoise out there where you can see literally exploitation attempts being observed in the wild by sensors, which is really powerful and useful as well. So, none of these sources are really comprehensive and monitoring all these does require some work because there can be a lot of noise mixed in with the signal.
And that said, if you don’t have a lot of money to spend, a lot of budget, but you do have vulnerability analyst time, these can be very, very useful. So if you do have money to spend, you do have budget by far the best option here is a commercial vulnerability intelligence feed. And we have done a ton of research into nearly all of the threat and sell providers out there. Have some pretty strong opinions about which ones are the best in this area in terms of vulnerability intelligence, vulnerability intelligence, just being a slice of threat intelligence. And what’s really nice with a lot of these feeds, these commercial feeds is that you have a small army of analysts kind of working behind the scenes to analyze and curate a massive amount of information to really answer the question of what’s being exploited in the wild along with 20 or 30 other really important questions about vulnerabilities. And there’s really no other source for this type of information.
Focusing on the Vulnerabilities That Matter
Steve: So moving on here, once you’re able to really identify those actively exploited vulnerabilities and ideally mitigate them, the next step is to focus on the vulnerabilities that are going to be exploited soon. Like I mentioned, this isn’t a perfect science, but there are resources out there to help. So the exploit prediction scoring system EPSS is one folks are talking about a lot lately. EPSS can predict with a really high degree of confidence, which vulnerabilities will be exploited in the next 30 days. So very useful project. Definitely suggests you check that out. Also, you can look at hacker forums, you can look at social chatter to track kind of discussions about exploit development for specific vulnerabilities and CVEs, can monitor GitHub and pay spend and actually see POC code being developed for CVE. So you can really get a sense for which vulnerabilities will be exploited soon with a lot of this information and tooling.
And then finally, moving to the very top. Here we’re trying to understand which vulnerabilities specifically are being exploited and targeted attacks against your organization or maybe other similar organizations in your sector or industry. And you might wonder why I bring these up last, goes back to my first point about this diagram. Don’t these vulnerabilities represent the highest risk to the organization? Yes they do, but I bring them up last for a few reasons. One is if you’ve mitigated all actively exploited vulnerabilities and all high risk exploit or high risk vulnerabilities that are going to be exploited soon, you’re pretty much done, right? Because these vulnerabilities at the very top are a subset of those. So that’s kind of one just kind of common sense reason.
But secondly, this is, it’s really hard to answer this question, it’s harder to answer this question than any other questions on this diagram because knowing which vulnerabilities are being targeted in your organization requires a level of sophistication that can take a long time to develop in an organization. So you’ll need a SOC team, you’ll need SOC analysts with the right tooling, with the right monitoring so that they can observe on the network, identify which vulnerabilities, identify exploitation attempts on your network, but then also be able to attribute them as targeted attacks, by specific threat actors and threat groups. And that’s not easy to do. That’s generally only very mature organizations that can do that well. So that’s why I bring it up last. And so if you’re just getting started, you really want some quick wins, and you’ll generally find the opposite here at the tip of the spear.
SSVC Decision Trees

Steve: So I want to just talk for a minute about this, just the general concept about operationalizing vulnerability intelligence, incorporating it into our processes to really help make risk decisions. And there are a few ways to do this, but we recommend today something called SSVC. And before I dive into that, I do want to just digress for a moment because you might be thinking, well, what about risk scores? What about vulnerability risk scores? And there are a lot of vendors that provide vulnerability risk scores, Nucleus has vulnerability risk scores. They can be super useful, super powerful for a lot of things, for certain things. They’re great at allowing you to establish a baseline of risk and monitor that baseline over time as an indicator of how well you’re doing with your program.
So great for reporting, great for dashboarding, scorecards – leadership loves this stuff. So, you still need risk scores, but there are some limitations and some drawbacks to risk scores that make them a suboptimal choice for making decisions about what and when to patch, especially in the context of high risk vulnerabilities. So I won’t go into all the details, but there’s basically some ambiguity there. But the risk scores aren’t really well understood generally enough by consumers and sometimes even by the vendors to make those decisions about the most high risk vulnerabilities.
That leads me to SSVC and this concept of decision trees. And if you haven’t heard of decision trees, which I’m guessing is most of you, most folks haven’t, you can just think of them like flow charts in that they give you a way to map decisions to specific outcomes and actions. And this concept of using decision trees for vulnerability management in particular was something that was documented by Carnegie Mellon, their SEI group, software engineering institute group. And they published a paper, I think three or four years ago, and they labeled it SSVC, which stands for Stakeholder Specific Vulnerability Categorization. So it’s a great paper, it’s about 70 pages.
TLDR is that decision trees or decision diagrams, some folks call them, they’re really the best tools that we have for deciding which action should be taken when high-risk vulnerabilities are discovered. And again, I’m not suggesting that you use risk scores or decision trees. There’s definitely a place for both. They just kind of serve different purposes. And so just to get started with decision trees, it’s a pretty straightforward process. You first define vulnerability risk levels and specifically which conditions must be met for a vulnerability to be categorized in each of the levels that you want to define and the levels you define are up to you. And then you want to determine which actions should be taken when vulnerabilities are discovered in each of those risk levels. And then finally, you want to just codify this in the form of a decision tree and those decision trees can live in your vulnerability management plan or policy document.
Generally, you have more than one so you certainly want to start simple, but you definitely might find that you need multiple decision trees for different types of vulnerabilities or maybe different teams. And that’s perfectly okay. You might have a decision tree for your DevOps team and application related vulnerabilities, and you might have a decision tree for your cloud security team. But the idea is that this collection of decision trees, that really will define how you want to respond to vulnerabilities across your entire organization and enterprise.
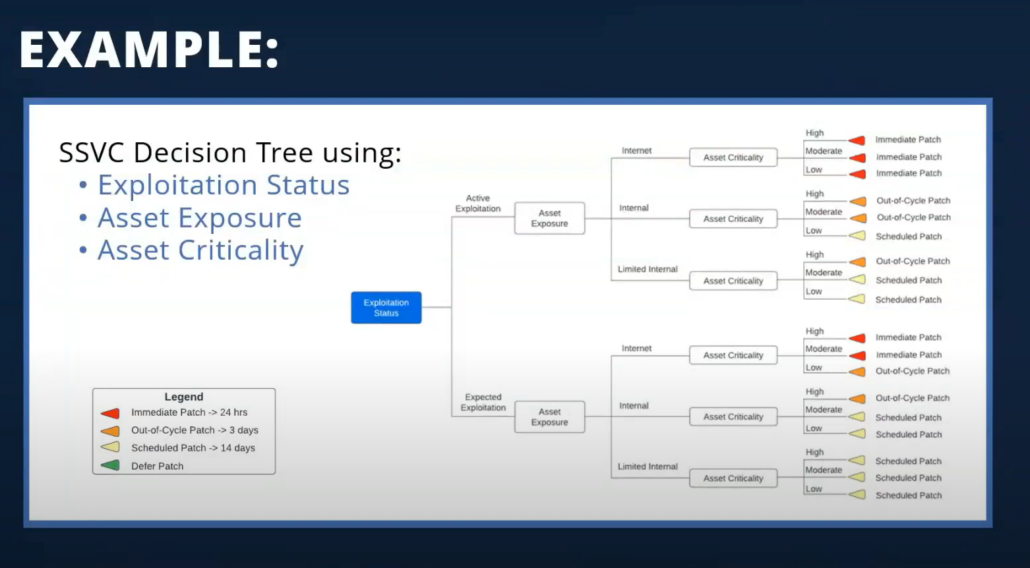
All right, so let’s take a really quick look at a simple, maybe oversimplified example of a decision tree or decision diagram. And in this example, we’re really centering our vulnerability response around the exploitation status of vulnerabilities. And that’s really the blue box here. In the legend on the bottom left, you can see we define four possible actions that we want to occur when specific conditions are met. So we either want to patch something immediately or within 24 hours, patch within three days at a cycle, do a scheduled patch within two weeks or basically defer and do nothing. And the idea is that a tree like this can be used to define and communicate your vulnerability management policy within a really large organization so that everyone understands, as an example, everyone understands when you have an actively exploited vulnerability and it’s impacting a internet exposed device, regardless of the asset criticality, the team isn’t leaving essentially until the vulnerability is patched.
So this diagram explains that policy in a simple and easily digestible way. And to me, the beauty of this whole thing is it really lies just in the simplicity of it and the precision that it brings to decision making, especially when compared to risk scores where no one can really answer or no one really understands the difference between a vulnerability that has a risk score of 997 and 998. It’s too much ambiguity there. So this really makes the decision making much more precise. And some people ask, do I have to create a diagram like this? The answer is really no. You could put all of the decision making logic and all of your associated actions and responses in a table format, but kind of defeats the purpose because if you’ve done that, you know it’s really difficult for the average person to process the information in that way and the average person to understand. So the graphical representation here is really a big part of it.
You may have noticed that the decision tree in this example does rely on asset context, specifically the asset exposure and asset criticality. I didn’t really mention asset context or asset anything much until this slide, but I bring that up because it actually is a great segue to the next couple of slides that I know Mr. Kuffer has been so patiently waiting to talk about. So I will pass the mic over to you, Scott.
Scott: To kind of piggyback off of everything that Steve has been talking about so far, when we’re thinking about the way that Nucleus likes to think about how we deal with vulnerabilities, you need to start thinking about orienting your vulnerability prioritization towards an action oriented model. So when you think about the two kind of broader themes of vulnerability management, there’s the, “Hey, we just don’t know what to fix first, we need the precision of priorities, so we need to know what our prioritization should look like.” And then the second is that we just can’t move fast enough. And so when you’re trying to address both of those larger issues, you need to be able to figure out and have tooling built in place to actually address either one of those different kind of big areas that you’re looking at.
And so a big part of where we normally propose organizations begin is the understanding what to fix first, because it’s a lot easier to say, “Hey, let’s get a better prioritization metric. Let’s orient our entire process around actions and what I would consider more realistic SLAs” and making sure we’re fixing the right vulnerabilities than it is to change an entire organization’s velocity when it comes to incident response and vulnerability management.
Leveraging Asset Context
Scott: So when we’re looking at the SSVC model, which is essentially categorizations of how things should or how different actions that your organization should take, one of the most important parts of that is asset context. So if you think about the traditional CVSS model where they even took your base score, your temporal score, and they tried to put those things together, what they’re trying to do is essentially take asset context, vulnerability context, and then some sort of impact context, then put all of that into one location.
Now, it didn’t really work out that way because everybody uses the CVSS base score because it’s very difficult to actually get your temporal scores and your impact scores. But when you look at a more modern approach to vulnerability management, this is what is necessary in order to adapt your processes to the modern enterprise, and then even to use a basic decision tree like Steve was showing in SSVC, that’s extremely valuable to what you’re trying to do and to how you prioritize. You can absolutely go down the path of vulnerability specific context. Is it currently being exploited in the wild? Is it currently being exploited in the wild and targeting organizations that look like me? That’s a great way to start. But when you want to start getting more specific and precise in the way that you prioritize for your organization, and then more importantly to be able to report progress and move up the organization, you need to be able to have the business context.
So what we normally see is it ends up being broken down across three different criteria, four, if you really want to get crazy with it. But the main three ways that we see it broken down are essentially what is exposed on the internet. So what can attackers outside the network see? So this is where organizations and companies like Security Scorecard and some ASM tools really come into play because that’s all they look at is your what’s publicly exposed on the internet. And the idea is that that gives you higher signal, higher value data to be able to use. But the beauty is that when you can take this and bring it into your larger vulnerability prioritization program and then apply an SSVC logical framework on top of it, it becomes extremely powerful very quickly. And then when you’re looking at not just your asset context about where it exists, but what does it do? You need to have a good idea of assets in order to know what you should do in terms of actions, right?
Because even your patch strategy might change based on what type of asset it is. If it’s an endpoint that’s processing a million dollars an hour in terms of payment card data or whatever, if you take that down with an errant patch or an auto patch, that’s a big problem. So you need to make sure that your change management processes are linked up with the actions that you need to take and that the priorities from the vulnerability side get communicated correctly to the different teams. So when we’re looking at assets and business context, we really can break it down to these three, which is where does the asset exist? How important of an asset is it? And what’s the type of data that exists on it?
So there’s a new concept coming around data security and data value. So when you want to get full context, and again, this is very difficult to do. I’m not saying this is an easy thing to do, that’s why tools exist out there specifically trying to help with just this problem. But if you have even a moderately good efficacy on your data around assets and business context, it allows you to provide such additional amazing public impact and context to your vulnerability information, which allows you to really enable SSVC style vulnerability prioritization at scale.
Automate Things That Don’t Scale
Scott: I think that leads us into the last one here, which is Steve mentioned at the beginning that a lot of this is around educational type of content. So it’s not just about Nucleus today. And one of the things that we’re big believers in is that you need to automate things that don’t scale. That’s a big part of this because if you look at a vulnerability management process, there’s a ton of occurring type of activities that need to happen.
I need to be able to take new data and I need that data in real time. I need to be able to go in and have analysts look at the vulnerabilities that I’m generating across my entire technology stack. I need to figure out what their work needs to be. Do they need to go enrich data with vulnerability intelligence? Do I need to go look up the data with the business context? So a lot of this information and activities are things that we need to be we to do to be effective, but if you just look around, just pop your head up out of the woodwork and start looking around to see what you can do, there’s actually a ton of different recurring what we would call menial type of tasks that can be automated. So generating the same report every month or every week. Figuring out who owns what vulnerabilities. There’s a process that you go through to figure out which vulnerability should be assigned to which person.
Now that can be really inefficient depending on the maturity of your organization, or you can get to a point where it just happens automatically and where kind of the Nucleuses of the world come in and where we start to see our main value is automating all of these types of tasks. But you can automate a whole bunch of tasking a whole bunch of different ways depending on the goals of your organization. Even just the concept of aggregating data across all of your different systems. For example, let’s say you have an application that has layers of technology around cloud, containers, virtual machines, and even just let’s say like a Kubernetes cluster. So when you’re trying to generate vulnerability data for just that application and getting the visibility on it, there’s a lot of de-duplication and normalization of data that you need to do to get a good picture of what that application actually looks like from a vulnerability perspective or answering the question, what’s running in production and what are the vulnerabilities that exist on those assets in production?
So when you start to just dig into the types of metrics and things that you’re normally looking to solve for, there are huge opportunities for automation. And so if you take one thing away from this, or one of the few things we would like you to take away from this is to start thinking about how you can automate all of those items that vulnerability analysts are really not trained to do. They’re trained to be vulnerability folks, not necessarily just doing the same task over and over again in a recurring manner in order to move the organization along. So that’s sort of the fifth area that we see is in every organization that we work with, there are huge opportunities for improvement there. You can even be doing a great job now and 10x,100x your output just by automating those things that aren’t even vulnerability management specific related or vulnerability related, but managing all of the administrative processes around the process.
Steve: I just want to add here, I know the context of this whole presentation is most kind of around large enterprises, but I know there’s some folks of smaller organizations online too. And for some small organizations that maybe aren’t growing super fast, you can get by with spreadsheets and manual processes and a small team and get the job done in a lot of these areas, but the bigger the organization is, the faster the organization’s growing, the more important automation becomes.
Operationalize Your Data

Scott: So the final thing that we wanted to show was to take some of the concepts that we talked about today and to apply it to what we see as a normal customer environment. So this is right here, kind of a anonymized sort of a sampling that’s representative of what we would consider a normal customer of Nucleus. And then to give you some context around the precision that comes into play when you use something like a decision tree. So you’ll see that we have the same kind of triangle concept that Steve showed earlier, but we have, basically the way we’re looking at is we have 59,000 devices. This is really focused around network devices, but this could be applied across any different type of asset that you care about, cloud resources, container image repositories, code repositories, et cetera. But let’s just sure, for the sake of argument and for simplicity, we’ve got 59,000 servers and workstations. Across all of those, we have about just under six million total vulnerabilities.
So if we think about that, it’s just even in the context of the speed that we would need to be able to execute on in order to reduce the risk in a really substantive way with a sledgehammer, right? Like CVSS, if over half of all vulnerabilities are high or critical, now we’re looking at almost three million vulnerabilities that you have to get fixed. And if your SLAs are set around critical vulnerabilities within 30 days and highs within 60 days, now you’re looking at, you have to fix three million vulnerabilities in 60 days as well as fixing all new vulnerabilities that get discovered. And it starts to become very overwhelming very quickly. So if you combine some of the context of the things that we were talking about earlier, so this triangle really represents a single branch of a decision tree, just so you can get an idea of this would represent stuff that we need to drop everything and fix now.
And so if we take that five million or six million vulnerabilities, and then we only look at our mission critical assets, so let’s only look at the assets that we know are maybe publicly exposed and that we rely on every day in order for our business to function. We’re now down to under a half million. So just by looking at the asset context, we dramatically decrease the amount of vulnerabilities that we have to focus on for this particular branch of, and we could decide on what types of actions we want to take. Now we could tone that down even further. We could say of these 449,000 vulnerabilities, which ones are currently being exploited in the wild? And when you look at that list, it’s 389. So now you’ve got 389 vulnerabilities out of the six million that you know really need to focus on and fix, and you could realistically or theoretically even stop there.
And that’s a small enough list that you could actually focus on that and get it done in a reasonable amount of time. You could set SLAs based on that. You have the ability to really get precise in how you’re organizing your work and how your teams are organizing your work. But you could keep peeling back the layers of the onion, right? So we’ve got exploited in the wild on mission critical assets, and then if we dig just a layer deeper and we look at what Mandiant considers a critical risk, so these would be remotely exploitable vulnerabilities. There’s a ton of attacks going on maybe associated with malware. So Mandiant, the threat intel vendor has labeled of those 389 vulnerabilities, nine of them to be critical risk. And so you now have a very specific set of vulnerabilities that you can focus on and you know what to do first.
And then if you wanted to de-duplicate those into something that nucleus calls unique findings, that gets you down to three. So you really have three action items out of those six million that from this one branch allow you to say, what do we want to have happen based on a set of criteria? And then being able to put all that together into a single decision making tree, your decision making workflow becomes extremely powerful very quickly because those three vulnerabilities, you can drop everything and respond to if you needed to, and then you could work your way down the triangle up to your more precise or to the broader vulnerabilities that you have in your environment. So just an example of how you can represent and use all this data, data that already most people already have, I should add, especially with the business context and the CISA KEV list, you have the ability to do all of this today. It’s just putting it together in a place where you can act on it in a central location.
Patrick: Hey Scott, there was a question earlier asking if there other tools to do this? One of the things they pointed out was not having budget for a commercial tool. And one thing I think is this triangle is a good way to go and explain to executives why you need budget for a tool like Nucleus, because it is a really, really big scale problem in focusing on those needles in a haystack.
Steve: Yeah, a lot of the sources of vulnerability intelligence that we were talking about, a lot of those are free and some cases open source. So we mentioned the KEV, we mentioned EPSS, we mentioned GreyNoise, which has a free version. So there’s a lot of this information out there. And the question is about having budget for a commercial vulnerability management tool, though.
Patrick: Yeah, I think from our experience, it takes people to stitch them together and keep it working is the real challenge. Especially when you’re talking about scale. So it just depends, I think like you said, what size they are and being able to really manage that. And the larger you get, the more challenging maintaining that and scaling that becomes.
Key Takeaways
Scott: From a takeaways perspective, it should be pretty clear here… vulnerability management is extremely important. And obviously Steve and I are biased and we’ve done this for a long time, so we absolutely of course believe that. But just a couple statistics to back up the way that we feel because we love data is that vulnerability exploitation is now the number one way that attackers breach organizations. It’s no longer phishing, it’s no longer supply chain, and it’s no longer credential stuffing attacks, it’s vulnerability exploitation, and nine times out of 10, it’s a vulnerability that you already knew about. It’s not a zero day. And so when you’re looking at the real way that that attackers are going to get into your organization, it’s through vulnerabilities and vulnerability management.
VM is now the weak link in the security industry to the point of it being, depending on who you ask, it’s anywhere between 38% to 71% of all breaches start with vulnerability exploitation. So obviously that’s a wide range, but it just goes to show that everybody agrees it’s an extremely difficult and important position to be in. But the status quo of what we’re doing is really just not working, I think is it’s a representation of the fact that vulnerability management programs have not been doing this correctly for a very long time. We’ve been expending a lot of effort and a lot of investment, but nobody’s adapted to the modern way of enterprise, right? Enterprises are moving faster and faster, but vulnerability management teams are kind of being left behind because again, you’re just being crushed with the amount of data that’s coming out.
We no longer have a discovery of vulnerability problem. The problems have shifted to a problem of data volume. So in a modern vulnerability management program, you have to use vulnerability data and asset data to actually adapt to do what you need to do, rather than relying on just, “Hey, we’re going to scan once a quarter and then we’re going to try to run patches on patch Tuesday.” That’s not good enough to actually solve the real problems that most organizations are seeing. And the best way that we see to do that is through an intelligence led program using tools like the CISA KEV list, using companies like Mandiant, Recorded Future to inform your vulnerability data that you’re getting from all these different tools, combining all of that into a central location, then automating at scale, all of the different tasks that you have to do as a vulnerability management analyst and team so that you can report up to the board level. Oftentimes we’re seeing this as a board level issue all the way down to the individual owner of the vulnerability who is generally not the vulnerability analyst. Could be a developer, could be a patch manager, could be a CISA admin, could be an ops team.
Depending on your organizational structure. You have different teams and different users that own vulnerabilities, and you need that visibility at every layer of the organization. And through the five areas that we talked about today is how we view kind of the foundation and setting the foundation for being able to have a successful vulnerability program going forward. And those are the main takeaways that we have for you today.
Interested in a quick run through inside Nucleus to see how some of this might be implemented in an application? Click here for a quick demo from Scott and Steve.

See Nucleus in Action
Discover how unified, risk-based automation can transform your vulnerability management.

