








































































Your Vulnerability Scanner Data Isn’t As Good As You Think
Your scan data is flawed. Let’s walk through some typical scanner pitfalls and how Nucleus helps.

Everything Your Vulnerability Scanner Knows Is Wrong!
I learned everything I need to know about vulnerability management at a U2 concert in September 1992. At that moment in time, a 66 MHz 486DX2 was a top-of-the-line computer, Linux was barely a year old, Windows NT didn’t exist yet, and neither did the World Wide Web, but they predicted my future. During a rapid-fire sequence of chaotic images on huge CRT screens, 5 words flashed by in an instant but etched permanently into my memory: EVERYTHING YOU KNOW IS WRONG.
Well, if only it were that easy. Some of it is wrong. Most of it isn’t. The difference between a vulnerability management superstar and a scrub who’s going to be doing something else in six months can be as little as that skill of being able to discern between the two.
The problem is, there aren’t enough of those superstars to deal with all that data flying around. A trio of security analysts who had that skill decided to try to turn that skill into an algorithm. The result was a web-based app running on a surplus workstation that slowly grew into what we now call Nucleus.
Duplicate Assets
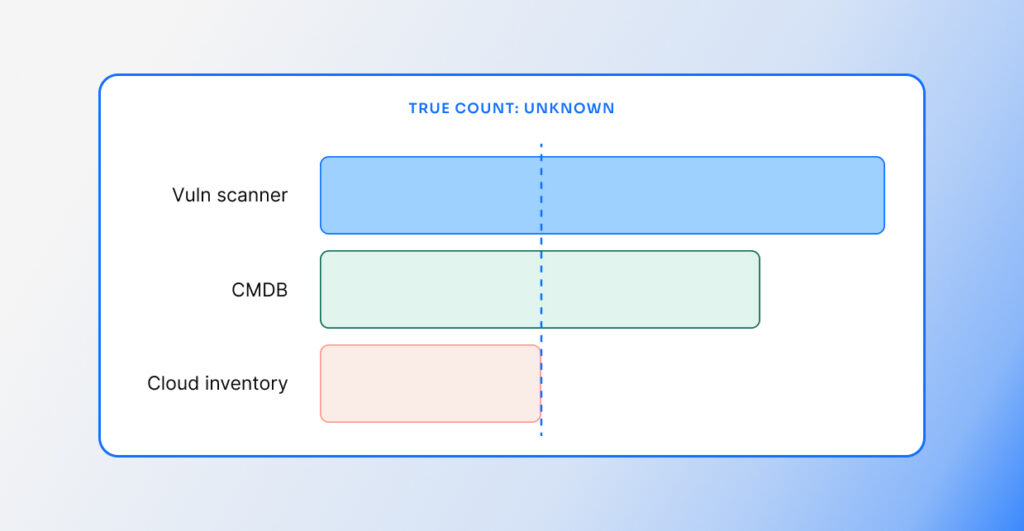
Duplicate assets are the problem we find most frequently today here at Nucleus. These can happen for any number of reasons, but the main one is that asset tracking in real time at enterprise scale is extremely difficult – and vulnerability scanners aren’t especially good at it. Then again, asset inventory systems aren’t especially good at asset tracking either. Nucleus is able to do a better job because we can look at a larger set of data than your scanner appliance has available at the time of your scan.
My first vulnerability management nightmare involved dealing with incomplete scans. We scanned every month, but our scan appliances didn’t have enough memory or CPU power – and we didn’t have enough of them – so our scans didn’t finish in 30 days. The data I got wasn’t bad, but we knew it wasn’t complete. The remediation teams didn’t want to act on it because it wasn’t complete, and it took me a few months to convince them there was enough good data there that we couldn’t ignore it. While a problem like this extreme is rare today, it’s still very common for assets to show up in one scan but not another. Today’s scans are still frequently incomplete, but the number of missing assets is smaller, so it’s harder to notice.
This is an aside, but I want you to remember it. It shouldn’t surprise you, but after I got the remediation teams to start acting on that data, we had fewer security incidents. Don’t make the mistake I made. Keep a pulse on the incident response side of things, and as you see the number of incidents go down, make sure the vulnerability management program and remediation teams get their fair share of the credit for the accomplishment.
Mixed Assets
Mixed assets are another fun one. This is one where vulnerabilities from two different computers get merged into the same asset. It’s most obvious when you see Windows vulnerabilities on a Linux or Mac system. Nothing causes a vulnerability management program to lose credibility faster than this one, but as long as you scan with authentication, this problem is rarer than it used to be. I have seen this happen several times in the last two years, and each time it happened, it turned out to be legitimate. If you have an Intel-based Mac with Bootcamp installed, your scanner will find that copy of Windows and report on the vulnerabilities in it. If you scan a load balancer with Windows systems behind it, the scanner may find Windows and Linux vulnerabilities on the same IP address because you have an embedded Linux system that is passing traffic from the Windows system behind it. Everything you know is wrong indeed.
Fales Positives and Negatives
By far the most common problem is false positives and false negatives. You hear about false positives all the time. False positives happen when a scanner reports a vulnerability that isn’t there. False negatives happen when a scanner fails to report a vulnerability that is there. You hear about false negatives more frequently in AppSec than in network scanning, because the only way you know you have one is if you scan with multiple scanners. But false negatives happen in network scanning as well. In my experience managing all of the major three scanner vendors in large enterprises, they all have a bigger problem with false negatives than with false positives. And the problem is more likely to happen soon after the signature is released. If it’s a high-profile vulnerability, rescanning after you see that the signature has been updated often clears the issue. But false negatives with obscure vulnerabilities persist until someone reports them.
How Nucleus Helps
U2 was right and wrong at the same time. They are very talented that way. EVERYTHING YOU KNOW IS WRONG is also wrong. Not quite everything you know is wrong – including some of the stuff in that vulnerability scan data. That’s why Nucleus can take that imperfect scan data, clean it up, and make it better.
Nucleus can’t fix all of the data quality problems that happen in vulnerability management, but we can help out significantly in three of them:
- Asset duplication
- Scan coverage
- False positives
Let’s take them one at a time.
Asset Duplication
When a vulnerability scanner reports duplicate assets, the same logic that we use to correlate findings from multiple scanners also helps to deduplicate those assets. This feature is a key purchase point for some of our customers. Duplicate assets are a frequent problem in large enterprises, and buying a risk aggregation tool is frequently the fastest way to solve the problem, especially when the problem is due to factors beyond the vulnerability scanner’s control like unhealthy Active Directory and unhealthy DNS.
Scan Coverage
While Nucleus can’t fix scan coverage issues, we make it more apparent when you have them. When you view your assets or your vulnerabilities in Nucleus, we give the date that we saw that asset or vulnerability. When everything goes right, if you scanned all those systems yesterday, all those findings will show yesterday’s date. We frequently get support cases that state that the dates don’t match, and ask if this is a bug. Investigating the data that Nucleus processed reveals that asset wasn’t in the scan in question. You may have scanned yesterday, but that doesn’t mean every system responded. We report the most recent data that we have. And we tell you when it’s out-of-date. If the data we have is several months old, we start color-coding it to make it stand out.
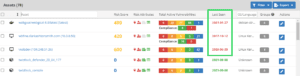
If the date next to a system is red, that serves to call into question whether that system may have been decommissioned. Some organizations do a better job of asset management than others. Some organizations are more aware of how good or bad they are at asset management than others.
If you have a problem with either asset management or scan coverage, Nucleus is good at helping you see the discrepancy and find that out so you can start solving it.
False Positives
Like scan coverage, Nucleus can’t do anything to improve the quality of your vulnerability scanner’s signatures. What we can do is make it easier to investigate and suppress false positives so you can stop arguing about them. Nucleus has facilities to change the status of a vulnerability to a false positive. Most of our competitors can also do that. However, we also allow you to upload your evidence. And since our integration with the ticketing system is usually bi-directional, if the System Administrator prefers to enter comments in the ticketing system, Nucleus pulls that information in so the security team can see all of the relevant information in one place.
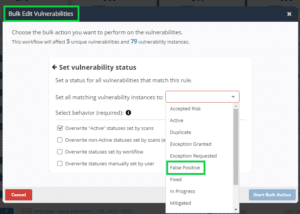
More importantly, when Nucleus sees that same vulnerability come in during future scans, it recognizes it and does not reopen the vulnerability. One of my greatest frustrations when I was a System Administrator was that every time the security analyst I worked with got promoted, I invariably had to refight and reprove every false positive we had on the books, since those records rarely got passed down from generation to generation. Nucleus neatly solves that issue.
Defending the Data
You want to trust your vulnerability scanner. Defending your vulnerability scanner is part of your job. All I need to do to get a 15-minute rant from you is to say 8 words: SCCM is more accurate than your vulnerability scanners. You’ve had to give that defense so many times, you practically have it memorized.
Why do I know? I’ve worked at a Fortune 20, a scanner vendor, and an MSSP. I’ve given the same defense at dozens of different companies. Potentially as many as 80.
I’ve also made vulnerability analysts want to hit me with a broom by telling infrastructure teams how many false positives they probably have. That’s one of those answers that makes everyone mad. The infrastructure team expects it to be millions. The security team expects it to be 0. And here I am saying it’s a few hundred, or a few thousand, it’s probably mostly on network devices, and by the way, you have more false negatives than false positives.
I wish the data were perfect. But the attackers don’t wait for our data to be perfect. If anything, they’re thriving on the chaos. What I had to learn to do to survive in this field was to understand the data, recognize its strengths and weaknesses, and use it to get the best results I could deliver. My goal was never perfection. My goal was to have a better month this month than we had last month. Or at least show a positive trend over each 90-day period.
My consistent game plan has served me well over the past 20 years – to act on the information that we’re confident is true, and when we discover problems, find and address the root cause when possible. And when not possible, clean up the data as best we can.
Avoiding the Logical Fallacy
In IT, there is a common logical fallacy I run into all the time. And it isn’t a new phenomenon. I was running into it in the 90s. The problem is discrediting an entire data set or a tool based on a single mistake.
Here’s an extreme example. Let’s say you have a history book. There’s a punctuation error on page 19. On page 38, it states that George Washington was the first President of the United States. George Washington’s status of being the first president of the United States exists independently of that punctuation error on page 19.
I can’t say I don’t trust the book until I find a bigger problem than that punctuation error. Even if I find multiple errors such as the statement that Hubert Humphrey was the 39th president of the United States, that still doesn’t mean the book is wrong about George Washington. It means the book is unreliable. It does not mean the book is always wrong.
People in other fields deal with this problem all the time. Historians come to mind. Anytime you deal with old information, it’s possible that some of the information is wrong, if only because something changed between the time the source was written and the current day. But the answer isn’t to throw it all out and say nobody knows. You find the information that solves the problem that you need to solve, look for corroboration from other sources when you have them, and cite where it came from.
That’s a reasonable summary of what they teach you in a first-year college writing class. It’s also a reasonable summary of the Nucleus algorithm for data analysis.

See Nucleus in Action
Discover how unified, risk-based automation can transform your vulnerability management.

